Agentic NetOps: The Right Direction, and the Real Work Ahead
NetBrain’s big announcement was so big, it took over the Sphere. But this was Cisco Live, so let’s talk about what Cisco had to say too. In his keynote, Jeetu...

Network management challenges for highly complex infrastructure are harder to overcome than ever. NetOps teams have been tasked with an enormous number of challenges. They solve thousands of tickets generated by tools like SolarWinds or ServiceNow daily. They also need to ensure network uptime across multi-hybrid networks, including:
In reality, many companies lack the resources to manage today’s complex networks. The more tasks teams have to manage manually in a short time, the more error-prone the system becomes. Regarding the network, operational disruptions can limit productivity for much longer than necessary.
Let’s discuss two main network management challenges every NetOps is facing today — maintaining around-the-clock uptime and achieving end-to-end visibility.
Network downtime can have a significant impact on your enterprise and processes, leading to:
The more secure your network, the better for your business.
Ensuring that all structures have sufficient visibility is essential when working with a hybrid network. Examples of structures present in hybrid infrastructures may include:
We’ll discuss these structures and others like them as they relate to network performance management below.
Enterprises experience thousands of IT events every day. Many are urgent, and they all require manual effort, causing longer resolution times. You know that your business can’t wait. How can you maximize network uptime and minimize MTTR from the public cloud to the data center to the access edge and everywhere in between, across branches and geographies? You need a certain degree of automation to perform a series of balancing acts. Let’s take a look at some possible steps.
If you work with IT Service Management (ITSM) platforms, look at the incidents your service desk works on. These tools usually give a very deep visibility into what problems occur day after day. Now, you can pick three to five common tickets and start automating them. But don’t start with the difficult ones — go step by step.
If you work with NetBrain, you should already have an integration with all your existing monitoring or ticketing tools. You can benefit from triggered diagnostic automation to:
After getting all this data, you can easily isolate the root cause and save your knowledge into an executable runbook.
NetBrain allows engineers to organize common troubleshooting steps into repeatable Runbooks (without coding!). When troubleshooting, junior engineers can leverage senior engineers’ expertise using these step-by-step diagnostics. You can analyze hundreds of potential issues across two devices or 200 in seconds.
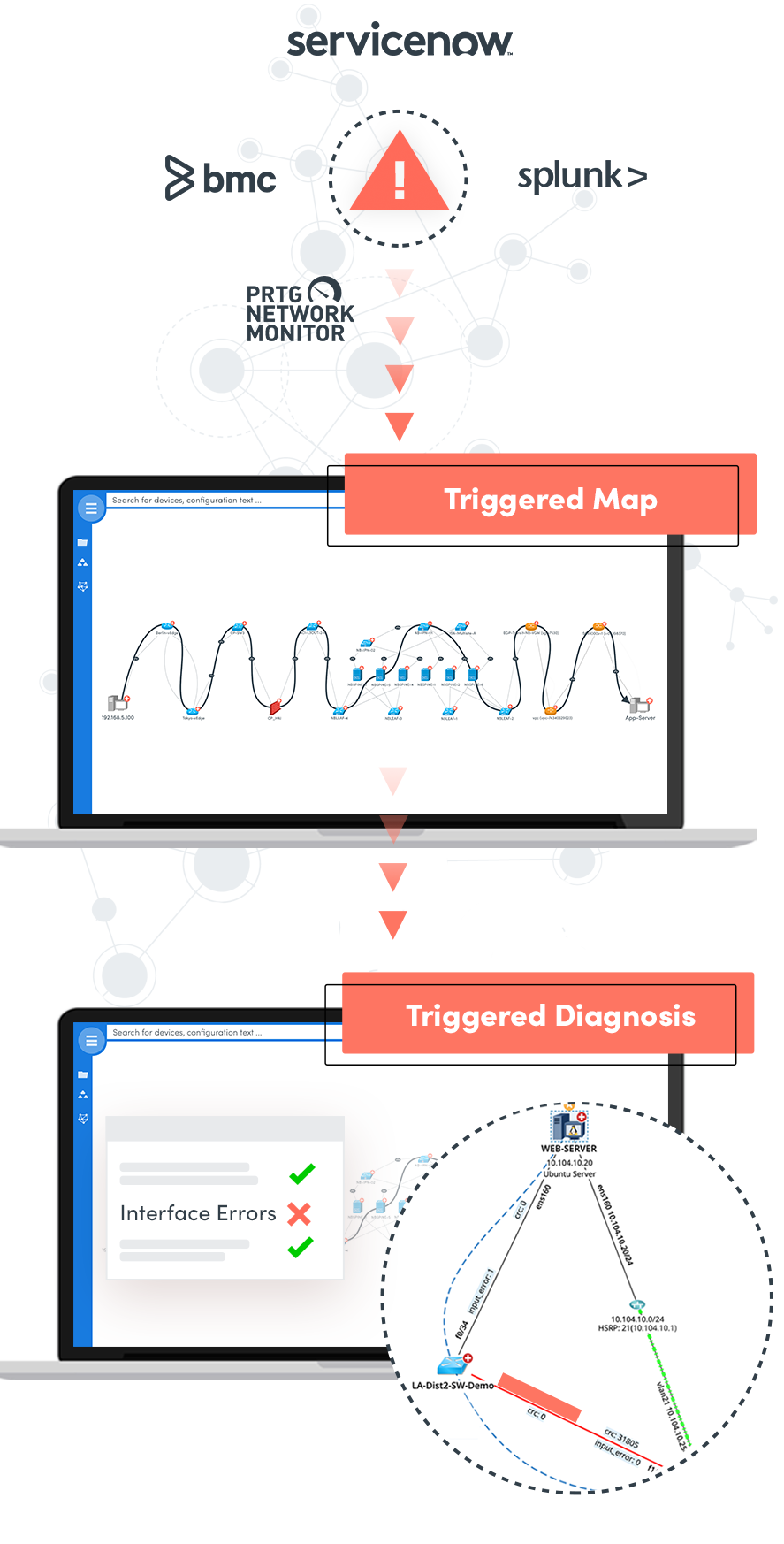
In this step, it is time to examine less common network issues. For these kinds of problems, NetBrain can easily and quickly create a map of the relevant part of the network on demand. It could be a path of an application flow or a site map and helps to provide visualization across any infrastructure, including:
Engineers can now use interactive Data Views to display additional information. Overviews help you see where to take action by letting you view routing protocols, interface information, QoS metrics, and more. Get visual support to understand the network’s state without having to use telnet/SSH for multiple devices.
All these troubleshooting steps are automatically documented and can be taken over by a Level 2 or Level 3 engineer.
Last but not least, to maximize network uptime, you need the entire IT team to work together to solve issues. NetBrain Incident Collaboration facilitates collaboration among NetOps, SecOps, DevOps, and other IT departments. It allows IT users to troubleshoot together and use their collective expertise to fix network issues faster.
Now that we have established that automation is a must, let’s see how it can help to manage your hybrid network and give you full visibility of any network data.
Many of today’s network infrastructures are moving from the traditional LAN/WAN toward SDN and a hybrid cloud model. This approach makes the network more complex despite the won agility for provisioning services. As a result, manual methods of documentation (like Visio) and troubleshooting (via CLI) no longer scale.
NetBrain discovers and decodes the entire hybrid infrastructure. It automatically maps the network end-to-end, allowing you to manage it from a single interface.

With NetBrain, you dynamically visualize each aspect of your traditional network. Explore the data center, campus, or WAN from both a layer-3 and layer-2 perspective.
NetBrain helps you visualize your ACI infrastructure from several perspectives, with views including:
This visibility allows the whole team, not just the architects who engineered it, to help troubleshoot ACI.
NetBrain helps teams visualize their NSX infrastructure and maps the relationship between the network and the VMs it runs on. VM and network teams are finally on the same page, working together to resolve problems. Learn more about NSX Mapping Automation.
The WAN has changed a lot, from frame relay to MPLS and IPSec VPNs. Now, SD-WAN is quickly gaining adoption. With NetBrain, it’s easy to dynamically map your WAN no matter what technology you use.
It’s often difficult to pinpoint the cause of a cloud application issue. Teams with a hybrid cloud may struggle to determine whose network the problem is on. NetBrain offers visibility across the entire shared network and helps IT teams collaborate with their cloud provider.
Network management challenges are a constant for IT teams. Automation is necessary to meet companies’ needs for continuous technology development. If you can achieve network uptime throughout the business across any (hybrid) network infrastructure, you’ve already won half the battle.