AI Agents
Frontier LLMs reason about networks using generic network knowledge. NetBrain's agents reason about yours. Built on the Context-Aware Digital Twin, Network Intents, and Skills that encode your organization's institutional knowledge, they navigate topology, run diagnostics, and surface conclusions the engineer acts on. Agents operate at whatever level of autonomy the team is ready for, from fully supervised investigation to diagnosis triggered automatically by incoming tickets and alerts. The engineer reviews the result rather than driving each step. Agents read by default, operate within role-defined scope, and maintain a full audit trail. Every network change requires human review or pre-approved automation.Deep Diagnosis Agent
An agentic system that performs root cause analysis independently. Manually prompted or triggered directly from a ticket, an alert, or a webhook, the Deep Diagnosis Agent runs a complete root cause analysis without human hand-holding. It navigates your unique network topology, executes relevant tests, synthesizes findings, and delivers a structured diagnosis ready for engineer review or automated action.
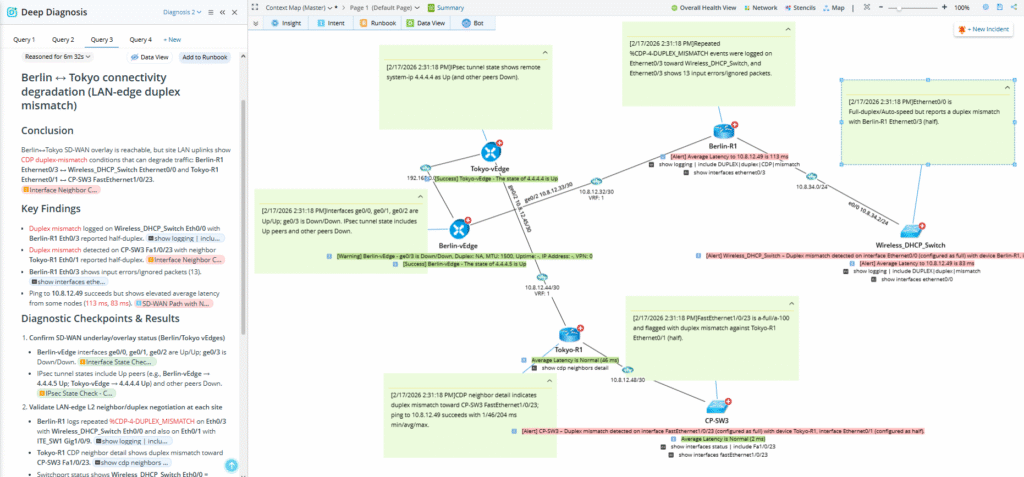
How the agent decides what to do
At the start of every session, the agent reads the descriptions of all enabled MCP tools. It matches those descriptions against the prompt using the underlying language model — no hardcoding, no routing rules. The right tools are called automatically based on what the task requires.
From event to diagnosis
- ITSM ticket opens or webhook fires. Triggered Automation Framework activates the Agent.
- The Agent reads available tools, pulls incident context, queries connected monitoring systems, and runs the relevant diagnostic intents.
- Output appears in NetBrain Incidents, the Incident Portal, and the originating ticket, with a Summary and View Full Diagnosis link.
- Engineer reviews and either acts on the recommended remediation or escalates.
Audit trails preserved end to end. No unsupervised remediation: action requires human review or pre-approved automation.
Runbook Companion Agent
Conversational intelligence over your existing runbook library. Engineers ask natural-language questions about runbook results, explore alternative remediation paths, and update runbooks with lessons learned from live incidents. Institutional knowledge becomes a living resource rather than a static document.
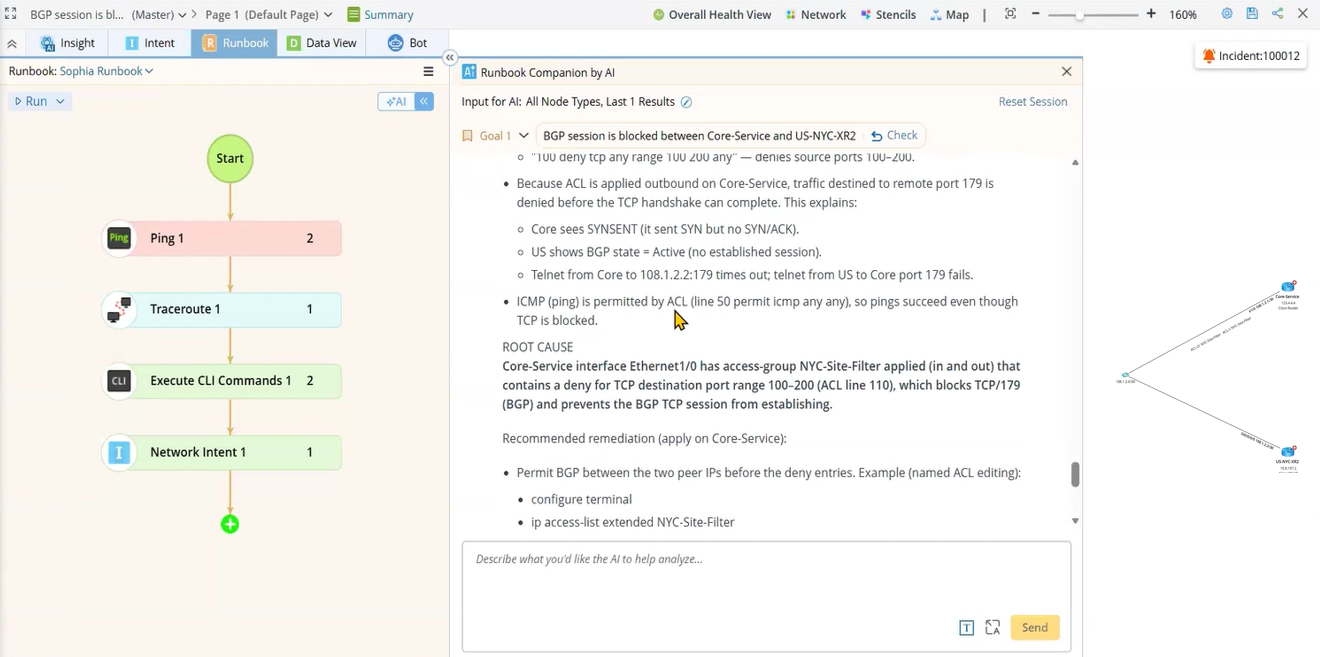
Change impact analysis, before you push
Before any change executes, the Companion reviews live configuration across every in-scope device and issues a push or do-not-push verdict per device — with the reason. It identifies which applications would be affected, drawing on both path data and configuration context. Engineers see a clear recommendation for every device before a single command is sent.
Post-change verification at scale
After execution, the Companion verifies success for every device in the change scope — condensed into a single line per device. What would otherwise be an unreadable diff across hundreds of devices becomes a concise, actionable summary.
Conversational intelligence over your runbooks
Ask natural-language questions about runbook results and get direct answers, not raw output.
When a runbook doesn’t resolve the issue, the Companion recommends the next automation to apply.
Generates concise summaries with initial conclusions — shareable without cleanup.
Example prompts
“Summarize the alerts in this runbook.”
“Show batch ping results as a table.”
“Why is voice quality poor between these endpoints?”
“What changed on these devices in the last 2 hours?”
Share context across the team
Pin frequent prompts as Goals so the team starts from a shared context, not a blank chat.
Share chat threads across teams — runbook intelligence is no longer locked in one engineer’s session.
MCP Bidirectional Integration
Most AI agents are built without network intelligence. NetBrain’s MCP Bidirectional Integration closes that gap in both directions: external agents from ITSM platforms, observability tools, and AI assistants can query NetBrain as a tool call, and NetBrain’s own Deep Diagnosis agent uses MCP to pull context from ServiceNow and other connected platforms before it diagnoses. For restricted environments, the MCP Server runs fully on-premises alongside a locally deployed model with no external API calls required.
ITSM & Workflow Automation
Your ITSM platform holds years of incident history: every ticket ever opened, every resolution path ever taken, every symptom description your team has written. That context is exactly what a network diagnosis agent needs before it starts reasoning. Without it, the agent is working from network data alone. With it, the agent knows what was happening in the environment when the incident started.
The connection runs both ways
NetBrain’s Deep Diagnosis agent uses MCP to pull ticket context from ServiceNow and other ITSM platforms before it runs a diagnosis. Incident description, related tickets, recent change history: all of it becomes input to the reasoning process. The diagnosis that comes back isn’t just grounded in network state; it’s grounded in the operational context surrounding the incident.
In the other direction, when your ITSM workflow is configured to call NetBrain’s MCP Server, it gains access to live network intelligence as a tool call. The ServiceNow or Jira agent can query topology, check device health along a path, or ask whether a known network fault matches the incident description, and incorporate that answer into how the ticket is handled. NetBrain returns the data; the workflow decides what to do with it.
Fewer escalations to network engineering. Less time spent on the first question every incident starts with: is this a network problem?
Application Observability
Application monitoring tells you degradation happened. It doesn’t tell you whether the fault is in the application layer, the infrastructure, or the network in between. Determining which requires pulling in expertise most observability teams don’t carry.
Cross-stack fault isolation
When an APM agent detects degradation, it can query NetBrain via MCP to ask whether a network fault is contributing. NetBrain traces the path between the affected endpoints, checks device health at every hop, and returns a verdict. The observability platform gets a direct answer, network fault or not, without standing up a separate investigation or opening a bridge call. Application engineers see the conclusion in the tool they’re already running.
When it is the network, NetBrain returns the device and interface implicated. When it isn’t, the application team can rule out the network with the same confidence.
Enterprise AI Assistants & Copilots
Enterprise AI assistants are increasingly how engineering teams get work done: research, summarization, status queries. But when the question is about the network, the assistant guesses. It has no view of your topology, no access to your device state, no connection to what’s actually running.
Network-aware answers from the assistant your team already uses
Connect Claude, Microsoft Copilot, or any LLM-powered assistant to NetBrain via MCP, and the assistant’s network queries are answered from the live digital twin rather than from training data. Current firewall state. Path validation between two sites. Configuration changes on a specific device over the last 48 hours. The assistant queries NetBrain, gets a factual response, and returns it to the engineer, accurately and in context, without requiring them to open a separate tool.
The answer is as current as the last NetBrain discovery. Not a cached report. Not a best guess.
Custom Agents & Internal AI Builds
Enterprise teams building their own AI agents face a consistent problem: network data access is hard. Raw CLI access is ungoverned. SNMP queries require infrastructure. Building a clean integration to live network state, covering device config, topology, and interface health, is months of work before the agent does anything useful.
Network context via MCP, with governance built in
NetBrain’s MCP Server gives custom agents a single integration point for topology queries, device state lookups, configuration history, and governed automation execution. Agents built on Claude, OpenAI, or any MCP-compatible framework can query NetBrain as a tool call, get structured network data back, and reason against it without owning the underlying data pipeline. Access is scoped to what the agent is permitted to see. Every query is logged. Automation executes within the guardrails the network team defines.
For teams operating in restricted or air-gapped environments, the MCP Server runs entirely on-premises alongside a locally deployed model. No traffic leaves the network perimeter. The same integration surface, topology, device state, and governed automation, is available without an external connection.
The agent reaches production-grade network intelligence without the team that built it becoming network engineers. Full MCP schema documentation and integration examples are available in the developer portal.
Proactive Change Validation
Network changes fail for a predictable set of reasons: the change touched something the engineer didn’t know was dependent on it, the network state had already drifted from the expected baseline, or a routing decision upstream made the downstream change wrong before it was pushed. Most of those failures are discoverable before the change executes, if the agent can see the network before it acts.
Pre-change network state verification
Before a change management agent executes a configuration update, it queries NetBrain: what is the current state of the affected devices, and what else does this path touch? NetBrain returns a topology-aware snapshot, including device health, active adjacencies, and any drift from baseline. If the state matches the assumption the change was built on, the agent proceeds. If it doesn’t, the agent surfaces the conflict before the push, not after.
Changes that would have caused an incident are caught at the validation step, not the incident review.
Integration Partners
Connected to the platforms running your operations.
NetBrain’s MCP Server publishes its network intelligence to any platform that speaks the Model Context Protocol. The connections below are available today. Any MCP-compatible system not listed can be connected through the same open architecture. On-premises deployments with a locally hosted model are supported for environments where external connectivity is restricted.
- AI Platforms & Assistants
Anthropic Claude | Microsoft Copilot | OpenAI
Connect your enterprise AI assistant to NetBrain and every network query it receives is answered from the live digital twin. The model is the same one you’re already using. What changes is the quality of the network data it reasons against: actual topology and device state, not training data approximations. NetBrain doesn’t replace the assistant. It makes its network answers accurate. - ITSM & Workflow
ServiceNow | Jira Service Management | PagerDuty
Every incident that reaches your ITSM platform can be pre-triaged with network context before a human reviews it. The ITSM agent calls NetBrain on ticket open, gets a network assessment back, and populates the record with findings. Tickets route with answers attached. Engineers spend their time on escalations, not investigation. - Observability & APM
Dynatrace | Datadog | Splunk | SolarWinds
Your observability platform sees what’s degraded. NetBrain tells it whether the network is the reason. Connect the two via MCP and your operations team gets cross-stack fault isolation, application layer and network layer in the same investigation, without needing a separate team or a separate tool to close the loop. - Network & Infrastructure
Cisco | Juniper | Arista | Palo Alto Networks | F5
NetBrain discovers and models your multi-vendor infrastructure continuously. The same topology, configuration, and device state it maintains for its own agents becomes the data source for every external agent connected via MCP. Your infrastructure doesn’t change. What changes is how many systems can reason against it accurately. - Custom & Internal Builds
Internal AI platforms | Chief AI Officer initiatives | MCP-compatible agent frameworks
Building your own agentic workflows? NetBrain’s MCP Server is the network layer. It exposes digital twin data, path analysis, device configuration, and governed automation execution as tool calls any MCP-compatible agent can invoke. The agent you’re building doesn’t need to solve network data access. NetBrain has already solved it.
Agent Skills
Teach NetBrain agents your network’s unique operational knowledge. Skills are the enabler that makes every NetBrain agent operate precisely on your specific environment rather than a generic network abstraction.
What Skills do
Encode network-specific expertise: internal troubleshooting procedures, operational guidelines, environment-specific dataCapture senior-engineer playbooks — the steps an expert would take for a specific class of incident — as deterministic procedures
Compound over time: every Network Intent encoded and every solved past problem makes Skills more reliable
No model retraining required. Skills sit on top of the foundation model.
How Skills work
Read once at the start of every agent execution — before any reasoning begins
Matched by description: the agent reads skill descriptions and selects the ones relevant to the current task
Act as guardrails, not scripts — short skills that nudge the agent in the right direction outperform long prescriptive ones; the agent handles the reasoning, the skill defines the boundaries
AI Document
AI-generated network documentation, automatically, from live operational data. NetBrain’s AI agents summarize network activities, translate operational findings into narrative documentation, and export Observability Dashboard content directly to Word or PDF. The agent reads the context-aware digital twin and the activity log, then writes the documentation the team would have written if they’d had the time.

- Auto-generate documentation for network diagrams, device configurations, and operational processes.
- Export in editable formats including Microsoft Word and Microsoft Visio.
- Include design and inventory data, diagnosis details, full configuration files, and routing tables.
- Translate Observability Dashboard snapshots into a narrative report ready for leadership.
- Sharable, audit-ready, current.




