Agentes de IA
Los expertos en derecho de vanguardia razonan sobre redes utilizando conocimientos genéricos de redes. NetBrainLos agentes de razonan sobre los tuyos. Construido sobre el Gemelo Digital Sensible al Contexto, Network IntentLos agentes, con habilidades que codifican el conocimiento institucional de su organización, navegan por la topología, ejecutan diagnósticos y presentan conclusiones sobre las que el ingeniero actúa. Los agentes operan con el nivel de autonomía que el equipo considere adecuado, desde la investigación totalmente supervisada hasta el diagnóstico activado automáticamente por tickets y alertas entrantes. El ingeniero revisa el resultado en lugar de dirigir cada paso. Los agentes leen por defecto, operan dentro del alcance definido por el rol y mantienen un registro de auditoría completo. Cada cambio en la red requiere revisión humana o automatización preaprobada.Agente de diagnóstico profundo
Un sistema autónomo que realiza análisis de causa raíz de forma independiente. Activado manualmente o directamente desde un ticket, una alerta o un webhook, el Agente de Diagnóstico Profundo ejecuta un análisis completo de la causa raíz sin intervención humana. Navega por la topología única de su red, ejecuta las pruebas pertinentes, sintetiza los hallazgos y proporciona un diagnóstico estructurado listo para la revisión del ingeniero o la automatización de la acción.
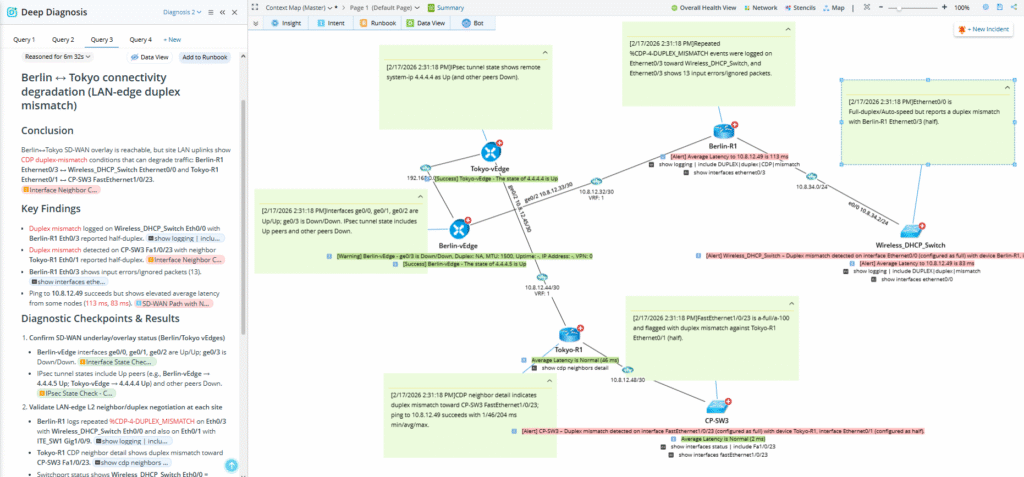
Cómo decide el agente qué hacer
Al inicio de cada sesión, el agente lee las descripciones de todas las herramientas MCP habilitadas. Compara dichas descripciones con la solicitud mediante el modelo de lenguaje subyacente, sin codificación fija ni reglas de enrutamiento. Las herramientas adecuadas se invocan automáticamente según lo que requiera la tarea.
Desde el evento hasta el diagnóstico
- Se abre un ticket de ITSM o se activa un webhook. El marco de automatización activado pone en marcha el agente.
- El agente lee las herramientas disponibles, obtiene el contexto del incidente, consulta los sistemas de monitorización conectados y ejecuta las intenciones de diagnóstico pertinentes.
- La salida aparece en NetBrain Incidentes, los Incident Portaly el ticket original, con un enlace de Resumen y Ver Diagnóstico Completo.
- El ingeniero revisa el caso y, o bien aplica las medidas correctivas recomendadas, o bien lo remite a un nivel superior.
Registros de auditoría preservados de principio a fin. No se permiten correcciones no supervisadas: cualquier acción requiere revisión humana o automatización previamente aprobada.
Runbook Agente acompañante
Inteligencia conversacional sobre su sistema existente runbook biblioteca. Los ingenieros hacen preguntas en lenguaje natural sobre runbook resultados, explorar vías de remediación alternativas y actualizar runbookCon lecciones aprendidas de incidentes reales. El conocimiento institucional se convierte en un recurso vivo en lugar de un documento estático.
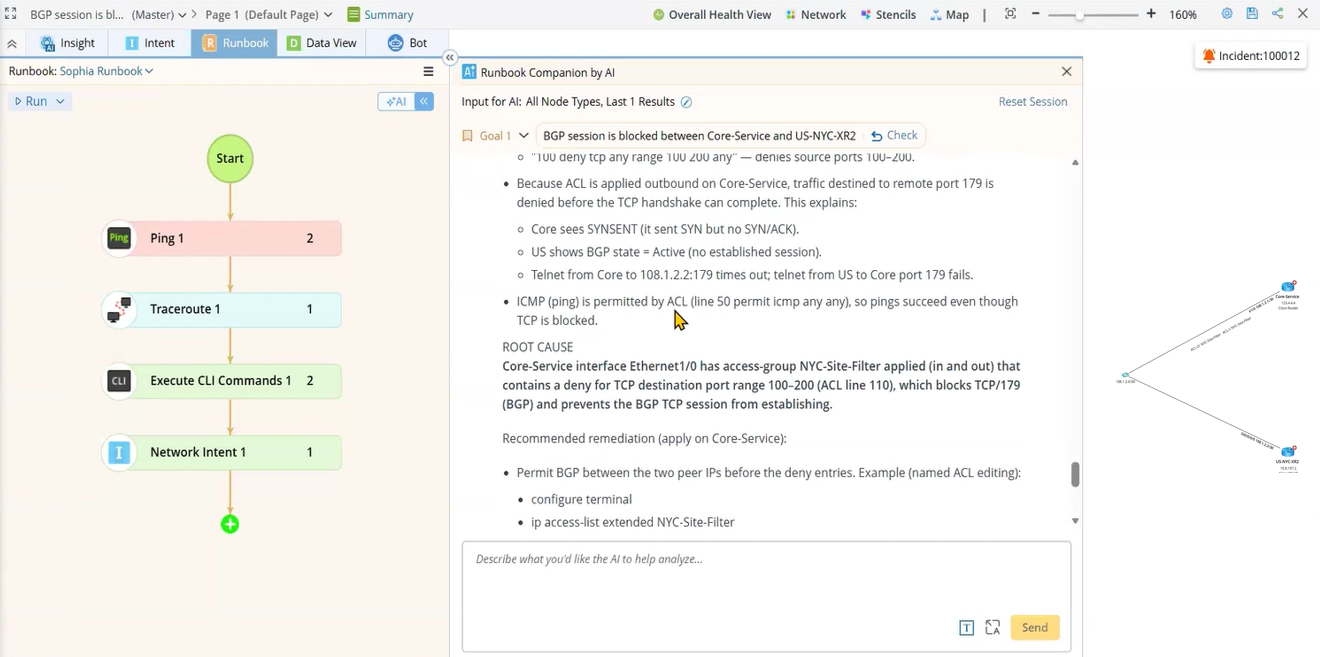
Análisis del impacto del cambio, antes de impulsar
Antes de ejecutar cualquier cambio, Companion revisa la configuración en tiempo real de todos los dispositivos incluidos en el ámbito de aplicación y emite una decisión (aplicar o no aplicar) para cada dispositivo, indicando el motivo. Identifica qué aplicaciones se verían afectadas, basándose tanto en los datos de ruta como en el contexto de configuración. Los ingenieros reciben una recomendación clara para cada dispositivo antes de enviar un solo comando.
Verificación posterior al cambio a gran escala
Tras la ejecución, Companion verifica el éxito en cada dispositivo incluido en el ámbito del cambio, condensando la información en una sola línea por dispositivo. Lo que de otro modo sería una comparación ilegible entre cientos de dispositivos se convierte en un resumen conciso y práctico.
Inteligencia conversacional sobre tu runbooks
Haz preguntas en lenguaje natural sobre runbook Obtenga resultados y respuestas directas, no datos brutos.
Cuando un runbook Si esto no resuelve el problema, el Companion recomienda aplicar la siguiente automatización.
Genera resúmenes concisos con conclusiones iniciales, que se pueden compartir sin necesidad de edición.
Indicaciones de ejemplo
“Resuma las alertas en este runbook."
“Mostrar los resultados del ping por lotes como una tabla”.
"¿Por qué la calidad de la voz entre estos puntos finales es deficiente?"
"¿Qué cambió en estos dispositivos en las últimas 2 horas?"
Compartir el contexto con todo el equipo.
Fija las indicaciones frecuentes como objetivos para que el equipo parta de un contexto compartido, y no de un chat en blanco.
Compartir hilos de chat entre equipos — runbook La inteligencia ya no está confinada a la sesión de un solo ingeniero.
Integración bidireccional de MCP
La mayoría de los agentes de IA se construyen sin inteligencia de red. NetBrainLa integración bidireccional de MCP cierra esa brecha en ambas direcciones: los agentes externos de las plataformas ITSM, las herramientas de observabilidad y los asistentes de IA pueden realizar consultas. NetBrain como llamada de herramienta, y NetBrainEl agente de diagnóstico profundo de MCP utiliza MCP para obtener información contextual de ServiceNow y otras plataformas conectadas antes de realizar el diagnóstico. Para entornos restringidos, el servidor MCP se ejecuta completamente en las instalaciones del cliente, junto con un modelo implementado localmente, sin necesidad de realizar llamadas a la API externa.
Gestión de servicios de TI y automatización de flujos de trabajo
Tu plataforma ITSM almacena años de historial de incidentes: cada ticket abierto, cada solución adoptada y cada descripción de síntomas que tu equipo haya redactado. Ese contexto es precisamente lo que necesita un agente de diagnóstico de red antes de comenzar a razonar. Sin él, el agente trabaja únicamente con datos de red. Con él, el agente sabe qué ocurría en el entorno cuando se produjo el incidente.
La conexión funciona en ambos sentidos.
NetBrainEl agente de diagnóstico profundo utiliza MCP para obtener el contexto de los tickets de ServiceNow y otras plataformas ITSM antes de ejecutar el diagnóstico. La descripción del incidente, los tickets relacionados y el historial de cambios recientes se incorporan al proceso de razonamiento. El diagnóstico resultante no se basa únicamente en el estado de la red, sino también en el contexto operativo que rodea al incidente.
En la otra dirección, cuando su flujo de trabajo ITSM está configurado para llamar NetBrainMediante el servidor MCP, se obtiene acceso a información de red en tiempo real como una llamada a una herramienta. El agente de ServiceNow o Jira puede consultar la topología, verificar el estado de los dispositivos a lo largo de una ruta o preguntar si una falla de red conocida coincide con la descripción del incidente, e incorporar esa respuesta en la gestión del ticket. NetBrain devuelve los datos; el flujo de trabajo decide qué hacer con ellos.
Menos incidencias escaladas al departamento de ingeniería de redes. Menos tiempo dedicado a la primera pregunta con la que comienza cada incidente: ¿es esto un problema de red?
Observabilidad de aplicaciones
La monitorización de aplicaciones indica que se ha producido una degradación. Sin embargo, no especifica si el fallo se encuentra en la capa de aplicación, la infraestructura o la red intermedia. Determinar la causa requiere conocimientos especializados que la mayoría de los equipos de observabilidad no poseen.
Aislamiento de fallas entre pilas
Cuando un agente APM detecta degradación, puede consultar NetBrain a través de MCP para preguntar si un fallo de red está contribuyendo a ello. NetBrain Rastrea la ruta entre los puntos finales afectados, verifica el estado del dispositivo en cada salto y emite un veredicto. La plataforma de observabilidad obtiene una respuesta directa, con o sin fallo de red, sin necesidad de iniciar una investigación aparte ni abrir una llamada de puente. Los ingenieros de aplicaciones ven la conclusión en la herramienta que ya utilizan.
Cuando se trata de la red, NetBrain Devuelve el dispositivo y la interfaz implicados. Si no es así, el equipo de la aplicación puede descartar la red con la misma seguridad.
Asistentes y copilotos de IA empresarial
Los asistentes de IA empresariales se utilizan cada vez más para que los equipos de ingeniería realicen su trabajo: investigación, resumen, consultas de estado. Pero cuando la pregunta se refiere a la red, el asistente adivina. No tiene visión de la topología, ni acceso al estado de los dispositivos, ni conexión con lo que realmente se está ejecutando.
Respuestas con reconocimiento de red del asistente que su equipo ya utiliza
Conecte Claude, Microsoft Copilot o cualquier asistente con tecnología LLM a NetBrain a través de MCP, y las consultas de red del asistente se responden desde el gemelo digital en vivo en lugar de desde datos de entrenamiento. Estado actual del firewall. Validación de ruta entre dos sitios. Cambios de configuración en un dispositivo específico durante las últimas 48 horas. El asistente realiza consultas NetBrainObtiene una respuesta objetiva y se la devuelve al ingeniero, de forma precisa y contextualizada, sin necesidad de que este abra una herramienta aparte.
La respuesta sigue siendo tan actual como la última. NetBrain Descubrimiento. No es un informe en caché. No es una estimación.
Agentes personalizados y compilaciones internas de IA
Los equipos empresariales que desarrollan sus propios agentes de IA se enfrentan a un problema recurrente: el acceso a los datos de red es complejo. El acceso directo a la interfaz de línea de comandos (CLI) no está regulado. Las consultas SNMP requieren infraestructura. Crear una integración fluida con el estado de la red en tiempo real, que abarque la configuración del dispositivo, la topología y el estado de la interfaz, supone meses de trabajo antes de que el agente pueda realizar alguna función útil.
Contexto de red a través de MCP, con gobernanza integrada
NetBrainEl servidor MCP de proporciona a los agentes personalizados un único punto de integración para consultas de topología, búsquedas de estado de dispositivos, historial de configuración y ejecución de automatización controlada. Los agentes creados en Claude, OpenAI o cualquier marco compatible con MCP pueden realizar consultas NetBrain Mediante una llamada a la herramienta, se obtienen datos de red estructurados y se analizan sin necesidad de controlar el flujo de datos subyacente. El acceso se limita a lo que el agente tiene permitido ver. Todas las consultas se registran. La automatización se ejecuta dentro de los límites definidos por el equipo de red.
Para equipos que operan en entornos restringidos o aislados de la red, el servidor MCP se ejecuta completamente en las instalaciones, junto con un modelo implementado localmente. No se produce tráfico fuera del perímetro de la red. La misma superficie de integración, topología, estado del dispositivo y automatización controlada están disponibles sin conexión externa.
El agente alcanza un nivel de inteligencia de red propio de un entorno de producción sin que el equipo que lo desarrolló se convierta en ingeniero de redes. La documentación completa del esquema MCP y los ejemplos de integración están disponibles en el portal para desarrolladores.
Validación proactiva del cambio
Los cambios en la red fallan por una serie de razones predecibles: el cambio afectó a algo que el ingeniero desconocía que dependía de él, el estado de la red ya se había desviado de la línea base esperada, o una decisión de enrutamiento anterior provocó que el cambio posterior fuera incorrecto antes de implementarse. La mayoría de estos fallos se pueden detectar antes de que se ejecute el cambio, si el agente puede visualizar la red antes de actuar.
Verificación del estado de la red previa al cambio
Antes de que un agente de gestión de cambios ejecute una actualización de configuración, consulta NetBrain¿Cuál es el estado actual de los dispositivos afectados y qué otros elementos toca esta ruta? NetBrain Devuelve una instantánea que tiene en cuenta la topología, incluyendo el estado del dispositivo, las adyacencias activas y cualquier desviación respecto a la línea base. Si el estado coincide con la suposición en la que se basó el cambio, el agente procede. Si no coincide, el agente detecta el conflicto antes de la actualización, no después.
Los cambios que podrían haber provocado un incidente se detectan en la fase de validación, no en la revisión del incidente.
Socios de integración
Conectado a las plataformas que gestionan sus operaciones.
NetBrainEl servidor MCP publica su inteligencia de red en cualquier plataforma compatible con el Protocolo de Contexto de Modelo (MCP). Las conexiones que se muestran a continuación están disponibles actualmente. Cualquier sistema compatible con MCP que no aparezca en la lista puede conectarse mediante la misma arquitectura abierta. Se admiten implementaciones locales con un modelo alojado localmente para entornos con conectividad externa restringida.
- Plataformas y asistentes de IA
Claude Antropológico | Microsoft Copilot | OpenAI
Conecte su asistente de IA empresarial a NetBrain Cada consulta de red que recibe se responde desde el gemelo digital en tiempo real. El modelo es el mismo que ya utilizas. Lo que cambia es la calidad de los datos de red con los que razona: topología real y estado del dispositivo, no aproximaciones de datos de entrenamiento. NetBrain No reemplaza al asistente. Simplemente mejora la precisión de las respuestas de su red. - Gestión de servicios de TI y flujo de trabajo
ServiceNow | Gestión de servicios Jira | PagerDuty
Cada incidente que llega a su plataforma ITSM puede ser preclasificado con contexto de red antes de que un humano lo revise. El agente ITSM llama NetBrain Al abrirse un ticket, se obtiene una evaluación de la red y se registran los resultados. Los tickets se enrutan con las respuestas adjuntas. Los ingenieros dedican su tiempo a escalar incidencias, no a investigarlas. - Observabilidad y APM
Dynatrace | Datadog | Splunk | SolarWinds
Tu plataforma de observabilidad detecta qué se ha degradado. NetBrain Indica si la red es la causa. Conecta ambos a través de MCP y tu equipo de operaciones obtiene aislamiento de fallas entre capas, tanto en la capa de aplicación como en la capa de red, en la misma investigación, sin necesidad de un equipo o herramienta aparte para completar el proceso. - Infraestructura de red
Cisco | Juniper | Arista | Palo Alto Networks | F5
NetBrain Descubre y modela continuamente su infraestructura multivendedor. La misma topología, configuración y estado de los dispositivos que mantiene para sus propios agentes se convierte en la fuente de datos para cada agente externo conectado a través de MCP. Su infraestructura permanece inalterable. Lo que cambia es la capacidad de los sistemas para interpretarla con precisión. - Construcciones a medida e internas
Plataformas internas de IA | Iniciativas del Director de IA | Marcos de agentes compatibles con MCP
¿Estás creando tus propios flujos de trabajo basados en agentes? NetBrainEl servidor MCP es la capa de red. Expone datos de gemelos digitales, análisis de rutas, configuración de dispositivos y ejecución de automatización controlada como llamadas a herramientas que cualquier agente compatible con MCP puede invocar. El agente que está creando no necesita resolver el acceso a los datos de red. NetBrain Ya lo ha resuelto.
Habilidades del agente
Enseñar NetBrain agentes el conocimiento operativo único de su red. Las habilidades son el habilitador que hace posible que cada NetBrain El agente opera con precisión en su entorno específico, en lugar de hacerlo sobre una abstracción de red genérica.
¿Qué habilidades tengo?
Codifique la experiencia específica de la red: procedimientos internos de resolución de problemas, directrices operativas, datos específicos del entorno. Capture los manuales de procedimientos de ingenieros sénior (los pasos que un experto seguiría para una clase específica de incidente) como procedimientos deterministas.
Acumulado a lo largo del tiempo: cada Network Intent codificado y cada problema anterior resuelto hace que las habilidades sean más fiables.
No se requiere ninguna capacitación adicional sobre el modelo. Las habilidades se basan en el modelo fundamental.
Cómo funcionan las habilidades
Lea esto una vez al inicio de cada ejecución del agente, antes de que comience cualquier razonamiento.
Coincidencia por descripción: el agente lee las descripciones de las habilidades y selecciona las que son relevantes para la tarea actual.
Actúan como guías, no como guiones: las habilidades breves que orientan al agente en la dirección correcta superan a las prescriptivas extensas; el agente se encarga del razonamiento, la habilidad define los límites.
Documento de IA
Documentación de red generada automáticamente mediante inteligencia artificial a partir de datos operativos en tiempo real. NetBrainLos agentes de IA resumen las actividades de la red, traducen los hallazgos operativos en documentación narrativa y exportan el contenido del Panel de Observabilidad directamente a Word o PDF. El agente lee el gemelo digital sensible al contexto y el registro de actividad, y luego escribe la documentación que el equipo habría escrito si hubiera tenido tiempo.

- Genera automáticamente documentación para diagramas de red, configuraciones de dispositivos y procesos operativos.
- Exportar en formatos editables, incluidos Microsoft Word y Microsoft Visio.
- Incluya datos de diseño e inventario, detalles de diagnóstico, archivos de configuración completos y tablas de enrutamiento.
- Traduzca las instantáneas del panel de control de observabilidad en un informe narrativo listo para la dirección.
- Compartible, listo para auditoría, actualizado.




